Header Image: Reddit: Actress Yvonne Craig (she was Batgirl from the original Batman series)
Abstract
The challenge1 had 2 tracks. Track 1 takes a single gray image as input. In track 2, in addition to the gray input image, some color seed (randomly samples from the latent color image) are also provided for guiding the colorization process.
Introduction
Currently, two broad approaches to image colorization exist: user-guided colorization and data-driven automatic colorization image.
The first category of approaches aims to propagate the color information (color strokes) provided by users and generate a visually plausible color image. Early colorization works follow the seminal work of Levin2 and formulate the guided colorization task as an optimization problem.
Another categories of works, which is more challenging, is the automatic colorization method. As there is not any color information of the scene, automatic colorization methods need to mine the semantics of the scene to help the colorization process.
Challenge
DIV2K Dataset
DIV2K has 1000 DIVerse 2K resolution RGB images with 800 for training, 100 for validation and 100 for testing purposes. The manually collected high quality images are diverse in contents.
Tracks
Track 1
Image Colorization without Guidance uses the gray version of color images as input, and aims to estimate the color information of the scene without any extra infor- mation. For the RGB to grayscale color space we use the standard commonly used linear transformation:
\[I = 0.2989 R + 0.5870 G + 0.1140 B\]Track 2
Image Colorization with Guidance provides, in addition to the input gray image from Track 1, some guiding color seeds as input. For each input image, we randomly sample between 5 and 15 pixels and provide the color information of these pixels along with their (x, y) image coordinates to help the colorization process.
Evaluation Protocal
The quantitative measures are Peak Signal-to-Noise Ratio (PSNR) measured in deciBels [dB] and the Structural Similarity index (SSIM), both full-reference measures computed between the colorization result and the ground truth (GT) color image.
As we found both the PSNR and SSIM index can not reflect the visual quality of the colorization performance, we also report the rank of subjective visual quality in this report. The subjective comparison is conducted in a non-reference manner, three people who do not know the ground truth color image compare the colorization results, and we rank the colorization results based on the comparison results.
Results
Architectures and main ideas
All the proposed methods in the challenge are deep learning based methods, with the notable exception of the method adopted by Athi team in the guided colorization track.
To enlarge the receptive field, most of the methods have adopted an encoder-decoder or the structure based on U-net. And the deep residual net (ResNet) architecture and the dense net (DenseNet) architecture are the basis for most of the proposed methods.
Restoration fidelity Generating
Generating high quality colorization estimation is still a very challenging task. The VIDAR team obtains the highest PSNR and SSIM scores on both tracks. In or- der to achieve high fidelity estimation they adopted only the RMSE loss in the training phase.
Perceptual Quality
Some visual examples of the colorization results provided by different teams can be found in Figure 1 for the Track 1 without guidance and in Figure 2 for Track 2 with guidance.

Although team VIDAR has achieved best PSNR and SSIM indexes, they actually did not generate much color information and the estimation still looks greyish.
In order to improve the perceptual quality, some teams have also adopted the perceptual loss or the Generative Adversarial Network (GAN) loss in the training phase.
Conclusions
This and the perceptual quality achieved by the proposed solutions indicates the difficulty of the image colorization task and that there is plenty of room for further improvements.
As expected the use of extra information un- der the form of several guiding color pixels helped into stabilizing and improving the colorization result. The deployment of deep learning solutions validated on other image to image mapping including restoration and enhancement tasks does not guarantee good perceptual results on the image colorization task.
The image colorization challenge is a step forward into benchmarking and further research is necessary for defining better losses for this task and also for designing solutions capable to see large contexts and infer plausible colors.
Methods
IPCV_IITM
IPCV IITM proposed a deep dense-residual encoder- decoder structure with multi-level pyramid pooling mod ule for estimating the color image from the gray input.
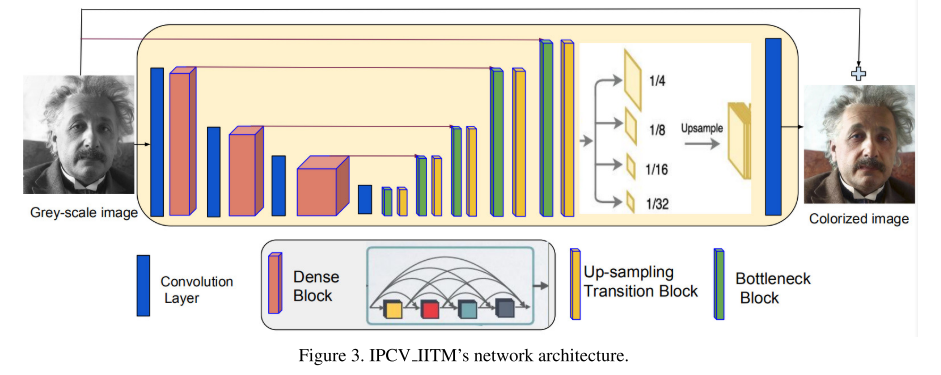
The proposed encoder is made of densely connected modules. It helps to address the issue of vanishing gradients and feature propagation while substantially reducing the model complexity.

Each layer in a block receives feature maps from all earlier layers, which strengthens the information flow during forward and backward pass making training deeper networks easier.

Athi
Athi team directly adopts the colorization network proposed in 3 to attend the no-guidance track.
While for the guided track, Athi team firstly creates a dummy image with colors from the guiding pixels and transfer the dummy image to the YCbCr space. For the in- put gray image, they assigned the gray values to R, G and B planes and converted from RGB to YCbCr color space. Then in the obtained Y channel of the input gray image, they check for the closest value in the Y channel of dummy image. And assign the corresponding Cb and Cr channel values to the output image, without changing the Y channel value.
This approach does not achieve RGB reconstruction results with high PSNR. But, in our non-reference subjec- tive evaluation test, the results generated by Athi outper- form in perceptual quality the results generated by some other algorithms which have much higher PSNR index.
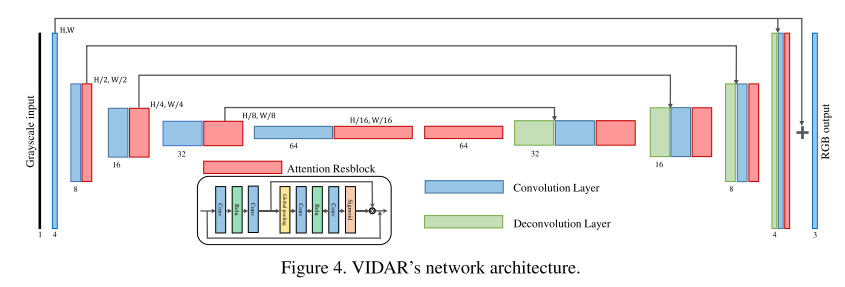
VIDAR
VIDAR team utilizes a regression method to colorize the grey images. VIDAR proposes a U-Net like network using the residual channel attention block to reconstruct color images from grey images.

Team_India
Team India proposes a framework for colorization of a gray scale image using a Self-Attention based progressive GAN.
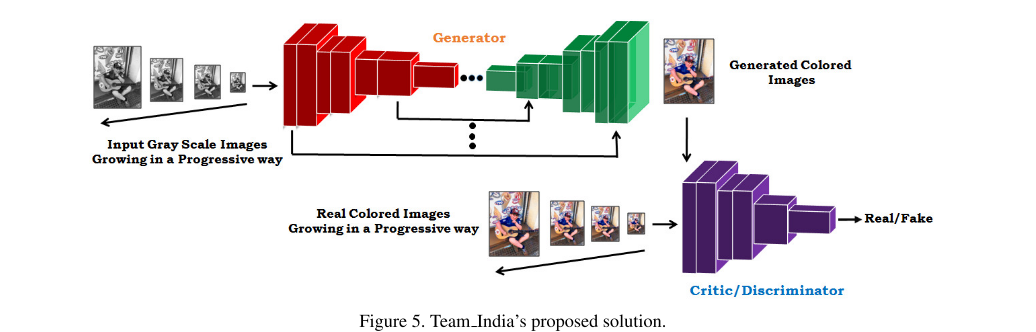
Technical Details:
- Self-Attention mechanism
- Progressive Growing of input channel
- Spectral Normalization for both generator and discriminator
- Higher critic to generator learning rate in our case 5:1 worked most efficiently
- Hinge based adversarial loss


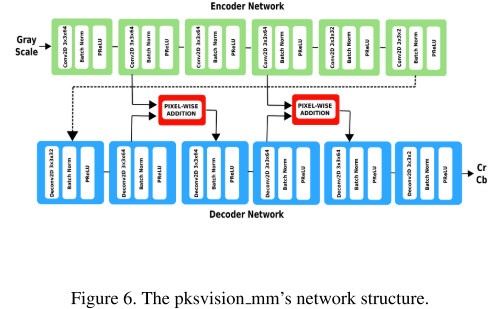
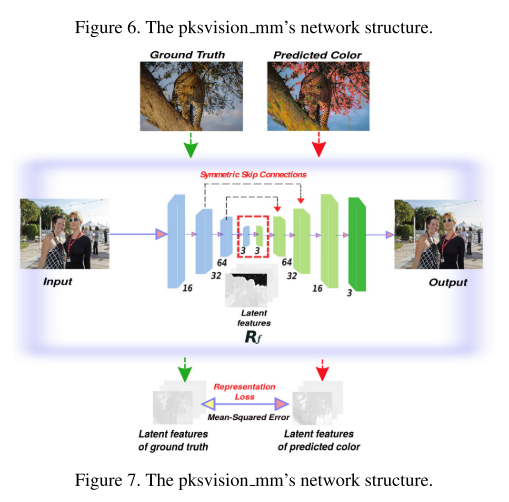
pksvision_mm
The model is based on the conditional Generative Adversarial Network (cGAN) framework.

ITU-GO
ITU-GO team uses the Capsule Network (CapsNet). The feature detector part of the original CapsNet model is updated with first two layers of VGG-19 and pretrained on ImageNet.

Reference
-
S. Gu, R. Zhang, A. N. S, C. Chen, and A. P. Singh, “NTIRE 2019 Challenge on Image Colorization : Report,” ↩
-
A. Levin, D. Lischinski, and Y. Weiss, “Colorization using optimization,” in ACM SIGGRAPH 2004 Papers on - SIGGRAPH ’04, 2004, p. 689. ↩
-
R. Zhang, P. Isola, and A. A. Efros. Colorful image col- orization. In European conference on computer vision, pages 649–666. Springer, 2016. ↩