Header Image: Reddit: Actress Natalie Wood (1938-1981)
Evolution
Automatic Colorization
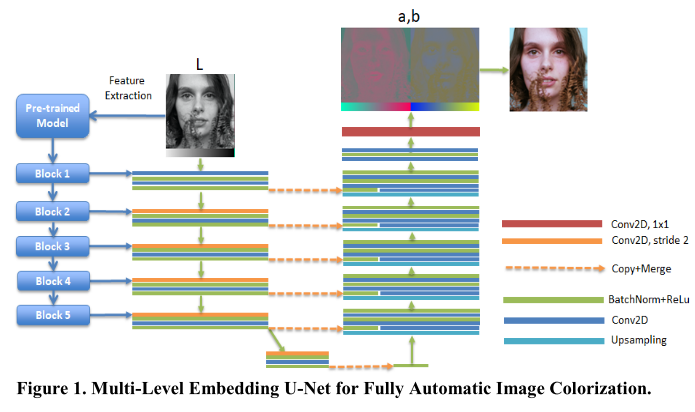
MLEU: Multi-Level Embedding U-Net for Fully Automatic Image Colorization
Overview
There are two main approaches to tackle this problem. Two main approaches are only different at last Conv2D of the expanding path by the number of output and activation function.
- Firstly, this problem is to solve from the regression view. It means that at every pixel of the input images, the model needs to learn a regression function to return two values a and b in the ab channel at the corresponding pixel
- In the second approach, every lightness value of the pixel will be classified into q bins receiving from the ab channel quantization process
We build our network as in based on U-net with the contracting path for encoding the lightness channel to the color features and the expanding path for decoding the color features into ab channel flexible.
Moreover, in the quantization process of ab channel into the discrete color bins, we apply the smoothness transform on prior color distribution to enhance the quality in the classification approach.
Preprocessing Input and Output data
\(I_l\) and \(I_{ab}\) are normalized in the range [0, 1].
The right image \(\hat{I}_{ab}\) has the values in the range smaller than the range of the left image \(I_L\). It means that the cells in our eyes determine brightness mainly, only very fewer for colors, which leads to the lightness layer is a lot sharper than the color layers. So, the regression approach has the mean effect to return the desaturated results.
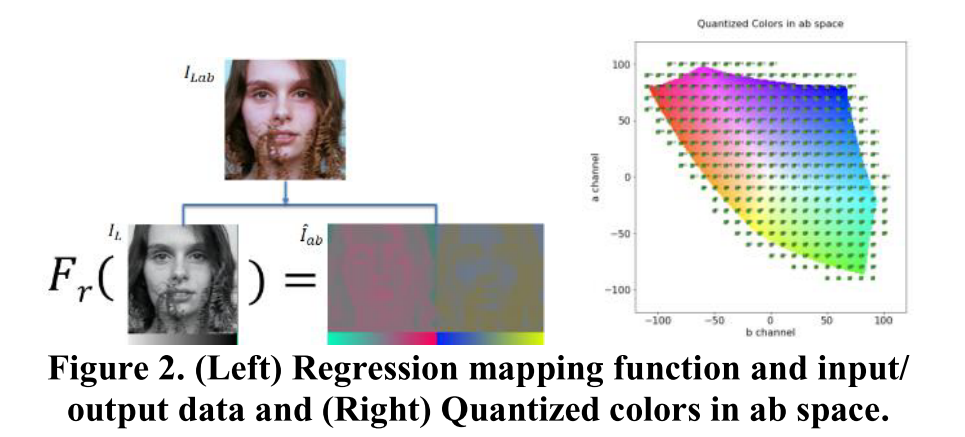
We achieve \(Y_{ab}\) by discretizing the ab channel into n bins. It is simply divided into the 2D grid by bins on the equal grid size. After that, we build \(F_q(Y_{ab})\) to transform \(Y_ab\) into \(Z_{ab}\). Firstly, \(Y_{ab}\) will be converted into a one-hot vector as the common output of the classification problems. The classification labels in this problem have relation together on 2D space. We need to express these relations by the weighted one- hot vector by applying the k-nearest searching for 5 nearest neighbors. All of them will be weighted by their distance using the Gaussian kernel with \(\sigma=5\). The role of the classification model is learning the mapping function \(F_c(I_L)=\hat{Z}{ab}\), where \(\hat{Z}{ab}\) is the predicted distribution over quantized color.
Smoothness prior distribution
We need to tackle the unbalance among the labels. Also, we choose the number of bins n = 313 and carry out the statistical analysis to make sense of the quantized color distribution on DIV2K dataset.
Still, this part is greatly borrowed from Richard Zhang’s objective Function and Class Rebalancing.
Network Structure
The contracting path produces the coarse feature maps by 5 encoding blocks. Every encoding block consists of the convolution layers, batch normalization layers, and ReLU activation functions. They will connect to 5 decoding blocks of convolutional, up- sampling layers, normalization layers, and activation functions at the same level in the expanding path by skip connection. The role of skip connection will help to prevent the loss of information by down-sampling from stride 2 from the last convolution layer in the encoding block. In the image colorization problem, the model uses stride 2 to down-sampling instead of the max-pooling layer at the end of the block to capture more details.
Besides, the pre-trained models from ImageNet will extract the features from the gray image. The last convolution layer 1x1 after the expanding path plays the role of a multi-layer perceptron network in pixel-level to classify or regress by the output values. In the classification, we use the soft-max activation function, and the sum of filters are the number of quantized-color bins. Otherwise, the convolution layer uses the tanh function and two filters.
ChromaGAN: Adversarial Picture Colorization with Semantic Class Distribution
A plausible color image is one having geometric, perceptual and semantic photo-realism.
The generator will not only learn to generate color but also a class distribution vector, denoted by \(y \in \mathbb{R}^m\), where \(m\) is the fixed number of classes.