Natural Language Processing with PyTorch
目标
- 发展对监督学习范式的清晰理解,理解术语,并发展一个概念框架来处理未来章节的学习任务
- 学习如何为学习任务的输入编码
- 理解什么是计算图
- 掌握PyTorch的基本知识
The Supervised Learning Paradigm
简单的监督学习,是指将Target(被预测的内容)的ground truth用于Observation(输入)的情况。例如,在文档分类中,目标是一个分类标签,观察(输入)是一个文档。
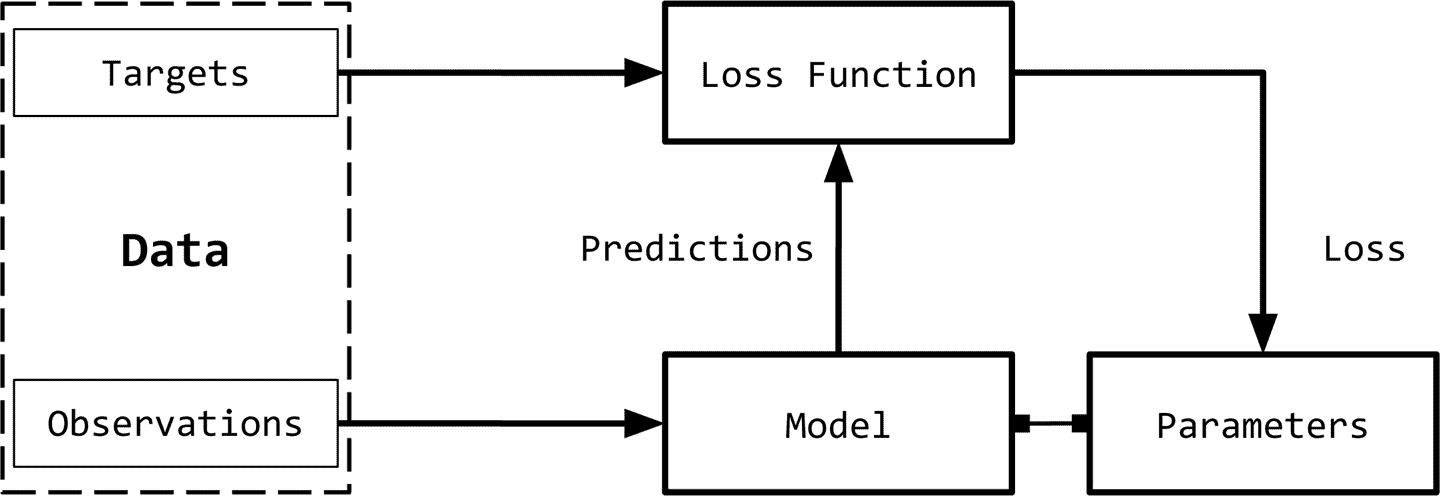
我们可以将监督学习范式分解为六个主要概念,如图1-1所示:
- Observations: 观察是我们想要预测的东西。我们用
x表示观察值。我们有时把观察值称为“输入”。 - Targets: 目标是与观察相对应的标签。它通常是被预测的事情。我们用
y表示这些。有时,这被称为ground truth。 - Model: 模型是一个数学表达式或函数,它接受一个观察值
x,并预测其目标标签的值。 - Parameters: 称为权重。标准使用的符号
w - Predictions: 预测,是模型在给定观测值的情况下所计算目标的值。目标
y的预测用\(\hat{y})\来表示这些。 - Loss function: 损失函数是比较预测与训练数据中观测目标之间的距离的函数。给定一个目标及其预测,损失函数将分配一个称为损失的标量实值。损失值越低,模型对目标的预测效果越好。我们用
L表示损失函数。
监督学习的目标是为给定的数据集选择参数值,使损失函数最小化。换句话说,这等价于在方程中求根。在传统的梯度下降法中,我们对根(参数)的一些初值进行猜测,并迭代更新这些参数,直到目标函数(损失函数)的计算值低于可接受阈值(即收敛准则)。
通常采用一种近似的梯度下降称为随机梯度下降(SGD)。在随机情况下,数据点或数据点的子集是随机选择的,并计算该子集的梯度。一般SGD算法有不同的变体,都是为了更快的收敛。
反向传播的每个步骤(又名epoch)由向前传递和向后传递组成。向前传递用参数的当前值计算输入并计算损失函数。反向传递使用损失梯度更新参数。
Observation and Target Encoding
我们需要用数字表示观测值(文本),以便与机器学习算法一起使用。下图给出了一个可视化的描述。
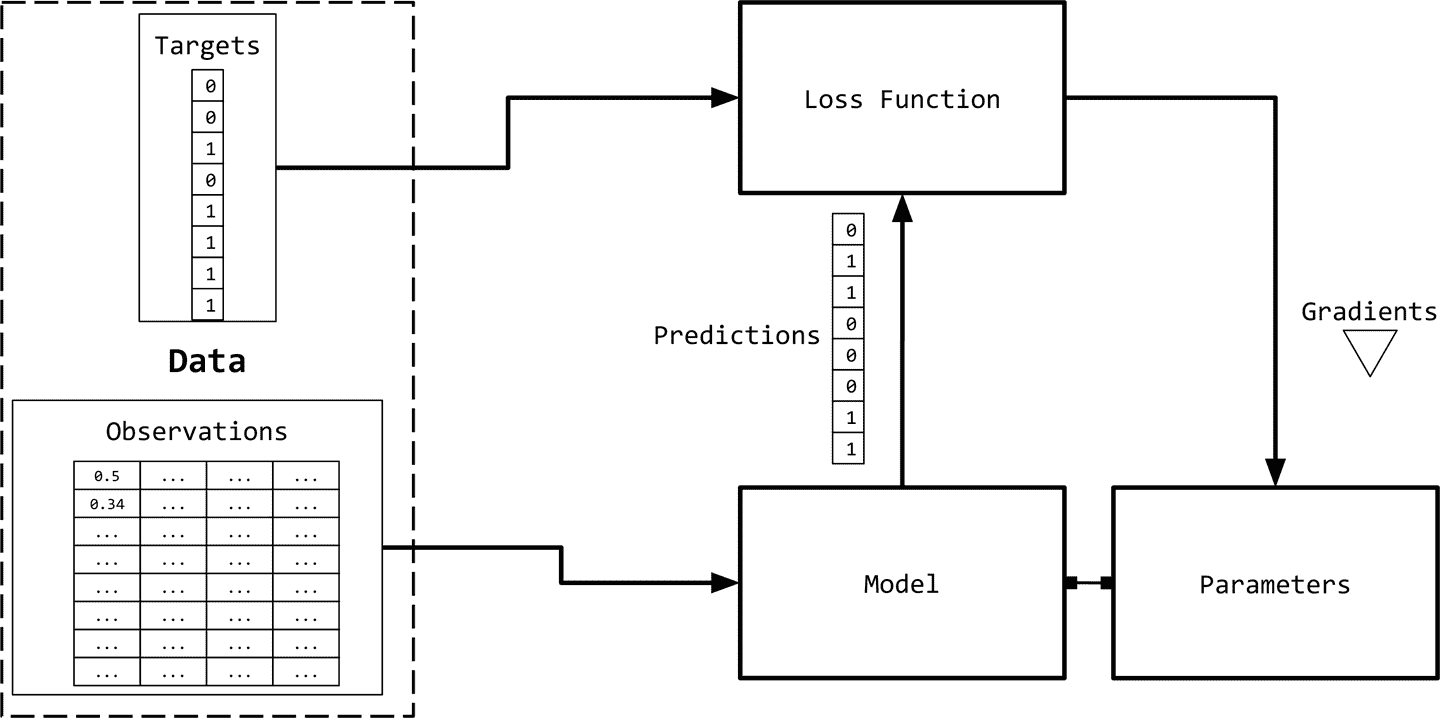
表示文本的一种简单方法是用数字向量表示。有无数种方法可以执行这种映射/表示。虽然简单,但是它们非常强大,或者可以作为更丰富的表示学习的起点。所有这些基于计数的表示都是从一个固定维数的向量开始的。
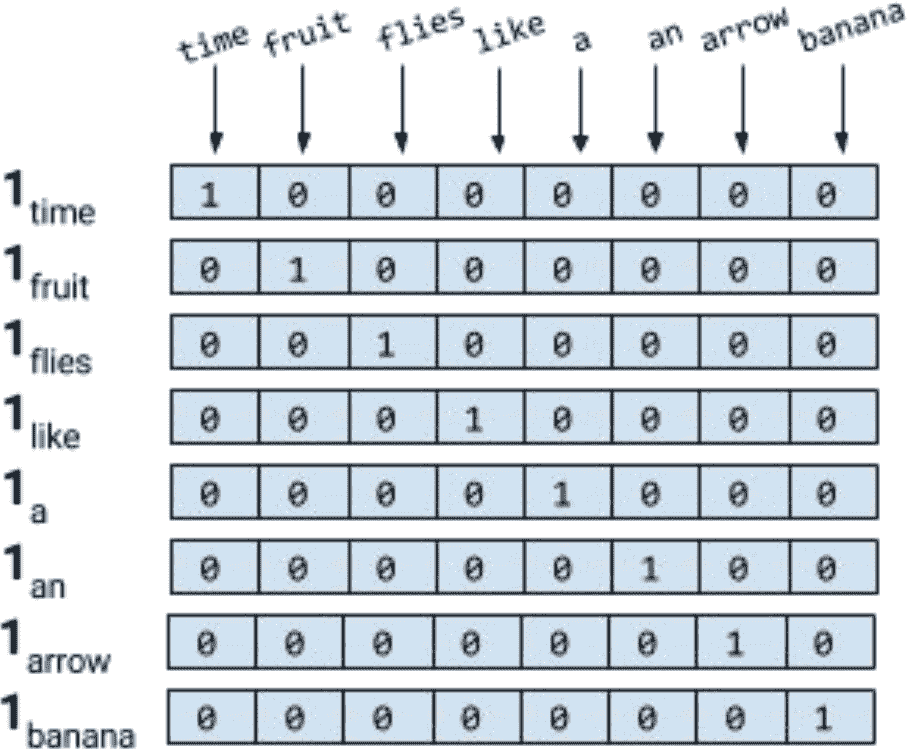
One-Hot Representation
顾名思义,one-hot表示从一个零向量开始,如果单词出现在句子或文档中,则将向量中的相应条目设置为1。
考虑如下两句话:
Time flies like an arrow.
Fruit flies like a banana.
对句子进行标记,忽略标点符号,并将所有的单词都用小写字母表示,就会得到一个大小为8的词汇表:{time, fruit, flies, like, a, an, arrow, banana}。所以,我们可以用一个八维的one-hot向量来表示每个单词。在本书中,我们使用 \(1_w)\的one-hot表示。
对于短语、句子或文档,压缩的one-hot表示仅仅是其组成词的逻辑或的one-hot表示。使用下图所示的编码,短语 “like a banana” 的one-hot表示将是一个 3×8 矩阵,其中的列是 8 维的one-hot向量。通常还会看到“折叠”或二进制编码,其中文本/短语由词汇表长度的向量表示,用0和1表示单词的缺失或存在。
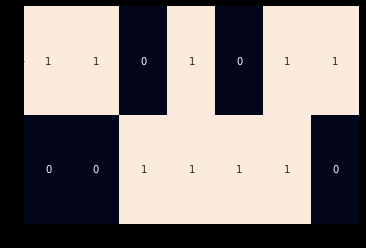
以下代码为例,对one-hot进行了可视化,得到一个折叠one-hot向量。折叠的onehot是一个向量中有多个1的onehot:
from sklearn.feature_extraction.text import CountVectorizer
import seaborn as sns
# 单词表
vocab = ['an', 'arrow', 'banana', 'flies', 'fruit', 'like', 'time']
# 语料库
corpus = ['Time flies flies like an arrow.',
'Fruit flies like a banana.']
# 使用sklearn自带的向量化函数
one_hot_vectorizer = CountVectorizer(binary=True)
# 将向量根据语料库进行拟合
one_hot = one_hot_vectorizer.fit_transform(corpus).toarray()
# 绘图
sns.heatmap(one_hot, annot=True,
cbar=False, xticklabels=vocab,
yticklabels=['Sentence 1', 'Sentence 2'])
结果如下:
TF Representation
我们现在介绍术语频率(TF)和术语频率反转文档频率(TF-idf)表示。这些表示在信息检索(IR)中有着悠久的历史,甚至在今天的生产NLP系统中也得到了广泛的应用。
短语、句子或文档的TF表示仅仅是构成词的one-hot的总和。例如句子:
Fruit flies like time flies a fruit.
这句话具有以下TF表示: [1,2,2,1,1,1,0,0]。注意,每个条目是句子(语料库)中出现相应单词的次数的计数。我们用\(TF(w)\)表示一个单词的TF。
TF-IDF Representation
考虑一组专利文件。您可能希望它们中的大多数都有诸如“claim”、“system”、“method”、“procedure”等单词,并且经常重复多次。TF表示对更频繁的单词进行加权。然而,像“claim”这样的常用词并不能增加我们对具体专利的理解。相反,如果“tetrafluoroethylene”这样罕见的词出现的频率较低,但很可能表明专利文件的性质,我们希望在我们的表述中赋予它更大的权重。反文档频率(IDF)是一种启发式算法,可以精确地做到这一点。
IDF惩罚常见的符号,并奖励向量表示中的罕见符号。 符号w的IDF(w)对语料库的定义为:
\[IDF(w) = \log Nn_w\]\(n_w\) 是包含单词w的文档数量,\(N\)是文档总数。TF-IDF分数就是TF(w) * IDF(w)的乘积。以下展示了英文句子使用 TF-IDF 的一个例子:
from sklearn.feature_extraction.text import TfidfVectorizer
import seaborn as sns
# 单词表
vocab = ['an', 'arrow', 'banana', 'flies', 'fruit', 'like', 'time']
# 语料库
corpus = ['Time flies flies like an arrow.',
'Fruit flies like a banana.']
# tfidf向量化
tfidf_vectorizer = TfidfVectorizer()
# 进行拟合
tfidf = tfidf_vectorizer.fit_transform(corpus).toarray()
# 绘图
sns.heatmap(tfidf, annot=True, cbar=False, xticklabels=vocab,
yticklabels= ['Sentence 1', 'Sentence 2'])
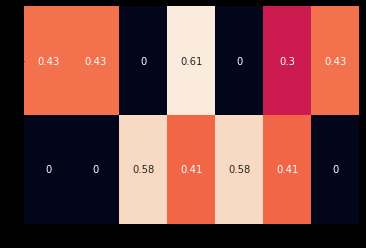
在深度学习中,很少看到使用像TF-IDF这样的启发式表示对输入进行编码,因为其目标是学习一种表示。通常,我们从一个使用整数索引的one-hot编码和一个特殊的“embedding lookup”层开始构建神经网络的输入。
Target Encoding
许多NLP任务实际上使用categorical标签,其中模型必须预测一组固定标签中的一个。对此进行编码的一种常见方法是对每个标签使用惟一索引。当输出标签的数量太大时,这种简单的表示可能会出现问题。
一些NLP问题涉及从给定文本中预测一个数值。例如,给定一篇英语文章,我们可能需要分配一个数字评分或可读性评分。有几种方法可以对数字目标进行编码,但是将目标简单地绑定到分类“容器”中(例如,“0-18”、“19-25”、“25-30”等等),并将其视为有序分类问题是一种合理的方法。
Computational Graphs
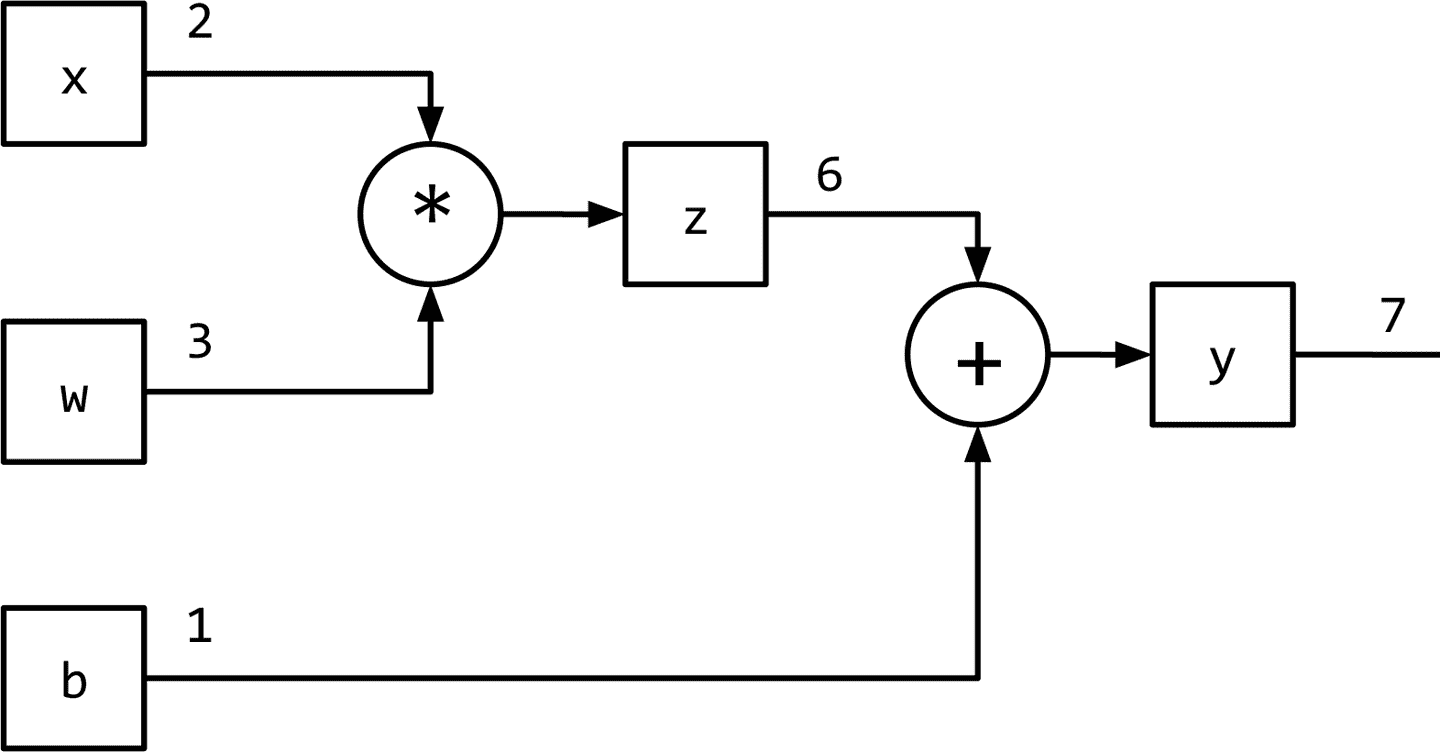
利用计算图数据结构可以方便地实现该数据流。从技术上讲,计算图是对数学表达式建模的抽象。让我们看看计算图如何建模表达式。考虑表达式:
\[y=wx+b\]这可以写成两个子表达式\(z = wx\)和\(y = z + b\),然后我们可以用一个有向无环图(DAG)表示原始表达式,其中的节点是乘法和加法等数学运算。作的输入是节点的传入边,操作的输出是传出边。因此,对于表达式,计算图如下所示。
PyTorch Basics
动态 VS 静态计算图
像Theano、Caffe和TensorFlow这样的静态框架需要首先声明、编译和执行计算图。虽然这会导致非常高效的实现(在生产和移动设置中非常有用),但在研究和开发过程中可能会变得非常麻烦。
PyTorch这样的现代框架实现了动态计算图,从而支持更灵活的命令式开发风格,而不需要在每次执行之前编译模型。动态计算图在建模NLP任务时特别有用,每个输入可能导致不同的图结构。
基本操作不再赘述。
Summary
重点是TF-IDF。TF应该很容易理解就是计算词频,IDF衡量词的常见程度。为了计算IDF我们需要事先准备一个语料库用来模拟语言的使用环境,如果一个词越是常见,那么式子中分母越大,逆文档频率越接近0。这里分母+1是为了避免分母为0的情况出现。
TF-IDF可以很好的实现提取文章中关键词的目的。