迁移学习
任务场景
- 把预训练的CNN模型当做特征提取器 得到已经在大数据集上训练好的模型,去掉最后一层全连接层,然后将剩下的全部网络结构当做一个特征提取器,原来的网络最后一层的输出就是你的特征,然后将该特征输入一个SVM分类器或者softmax分类器就可以快速实现你自己的分类任务。
- finetune model 这也是最常用的,因为一般我们并不会简单的把模型像1一样当做特征提取器使用,而是让模型去fit我们的训练数据,使得性能更好。因此我们除了像第一步里面一样去掉最后一个FC层以外,在网络训练过程中还要更新权重,进行BP传播。最简单粗暴的就是对修改后的全部网络层进行权重更新(当自己的数据库较大时),但是当我们本身任务的数据库较小时,为了避免过拟合,我们需要对网络的前几层固定参数(不更新权重),而只更新网络结构的后面几层。这是因为网络的前几层得到的特征是比较基础local的特征,基本适用于全部任务(边缘,角点特征),而网络层数越高的层,和数据库全局信息联系越紧密,(网络越靠后,信息越global,越靠前,越local,local的信息是多数情况共享的,而global的信息和原图紧密相关)。
- 预训练模型 可以直接使用别人发布的预训练模型来finetune。
新任务数据集和任务域
- 新的数据库较小,并且和pre-trained model所使用的训练数据库相似度较高: 由于数据库较小,在进行finetune存在overfit的风险,又由于数据库和原始数据库相似度较高,因此二者不论是local feature还是global feature都比较相近,所以此时最佳的方法是把CNN网络当做特征提取器然后训练一个分类器进行分类
- 新的数据库较大,并且和pre-trained model所使用的训练数据库相似度较高: 很明显,此时我们不用担心overfit,因此对全部网络结构进行finetune是较好的。
- 新的数据库较小,并且和pre-trained model所使用的训练数据库差异很大: 由于数据库较小,不适合进行finetune,由于数据库差异大,应该在单独训练网络结构中较高的层,前面几层local的就不用训练了,直接固定权值。在实际中,这种问题下较好的解决方案一般是从网络的某层开始取出特征,然后训练SVM分类器。
- 新的数据库较大,并且和pre-trained model所使用的训练数据库差异很大: 本来由于数据库较大,可以从头开始训练的,但是在实际中更偏向于训练整个pre-trained model的网络。
迁移学习技巧
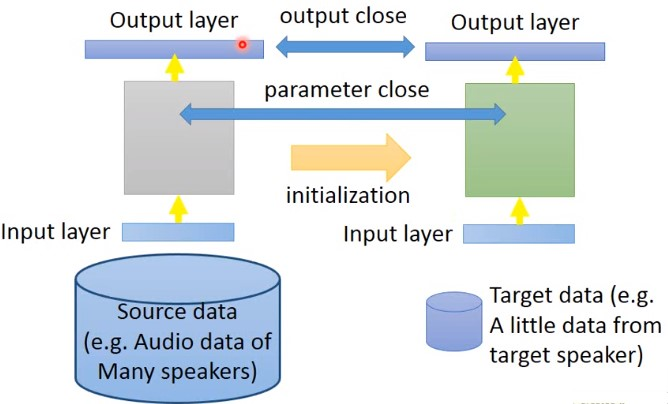
Conservation Training
例如,已经有大量的source data数据(比如语音识别中大量的不同speaker的语音数据),以及target data(某个speaker的语音数据)。此时如果直接用source data训练出来的模型,再用target data做迁移学习,模型可能就会坏掉。可以在training的时候,加一些限制(就是加一些非L1,L2的正则化),使得训练完成之后,前后两次模型效果差不太多。
Layer transfer
先用源数据训练出一个模型,然后将这个模型的某些层网络直接复制到新的网络中,然后只用新数据训练网络的余下层网络。这样训练时只需要训练很少的参数。
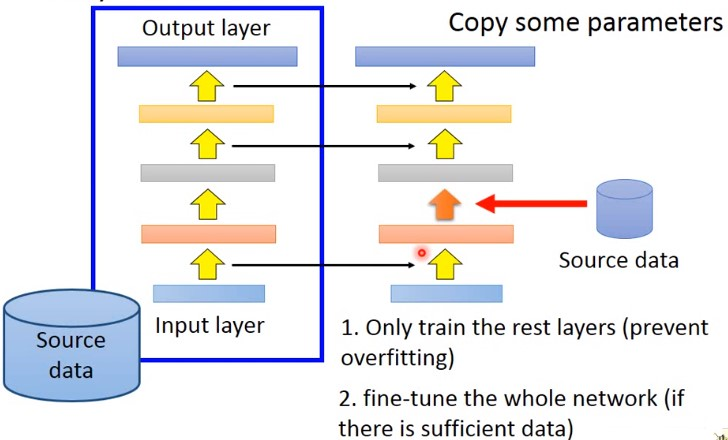
哪些层应该被transfer,哪些不应该被transfer? 不同的任务之中,需要transfer的网络层不同。
语音识别中,通常只复制最后几层网络。然后重新训练输入层网络。(同样的发音方式,得到的结果不同)语音识别的结果,应该跟发音者没有关系的,所以最后几层是可以被复制的。而不同的地方在于,从声音信号到发音方式,每个人都不一样。
在图像任务中。通常只复制前面几层,而训练最后几层。通常前几层做的就是检测图像中有没有简单的几层图形,而这些是可以迁移到其他任务中。而通常最后几层通常是比较特异化的,这些是需要训练的。
建议
- 不要随意移除原始结构中的层或者更改其参数,因为网络结构传导是一层接着一层的,你改了某层的参数,在往后传导的过程中就可能得不到预想的结果。
- Learning rates学习率:不应该设置的太大,因为我们finetune的前提就是这个模型的权重很多是有意义的,但是你学习率过大的话就会存在更新过快,破坏了原来好的权重信息,一般在finetune时学习率一般设置在1e-5,从头开始训练的话可以设置的大一点:1e-3。
FEATURED TAGS
Computer Vision
Colorization
Deep Learning
Papers
Technical Writing
Computer Graphics
Tutorials
Mathematics
Graph Neural Network
Biomedical
Natural Language Processing
Graph Theory
Neural Network
Reinforcement Learning
Markov Decision Process
Paper Reading
Games
GVGAI
VGDL
MCTS
Clustering
Unsupervised Machine Learning
Social Science