三维数据深度学习
三维数据
3D数据与2D数据最大的区别即在于数据的表现形式。众所周知,2D数据可以表示为一个二维矩阵,但3D数据通常有许多种表现形式:深度图、点云、网格、体积网格(volumetric grids)。

3D数据的表达形式通常由应用驱动,例如在计算机图形学中做渲染和建模通常我们选择网格化数据,而将空间进行三维划分我们一般使用体积网格等,而在3D场景理解时,我们一般使用点云。
以三维点云为例,我们分析其优势为:
- 点云非常接近原始传感器的数据集,激光雷达扫描之后输出的数据即为点云,深度传感器(深度图像)只不过是一个局部的点云,原始的数据可以做端到端的深度学习,挖掘原始数据中的模式
- 点云在表达形式上是更为简单,原始的点云信息是一组无序的三维点坐标。相比较来说,网格需要选择面片类型、体积网格需要根据分辨率选择网格的大小等,深度图需要注意拍摄的角度,表达也不全面;
当然,三维点云数据同样具有许多的缺点:
- 如果直接使用3D的卷积神经网络,其计算复杂度很高。通常大家会刻意的降低分辨率来减少复杂度,而降低分辨率会带来量化的噪声错误;
- 如果考虑不计复杂度的栅格,由于传感器只能扫描到表面,因此会导致大量的体积网格都是空白,所以体积网格并不是对3D点云很好的一种表达方式;如果用3D点云数据投影到2D平面上用2D卷积神经网络进行训练,这样会损失3D的信息;
- 在深度学习大热之前,多数研究倾向于在点云中提取手工的特征,再接FC,由于手工特征的局限性,限制了点云信息的表达。
点云数据在欧式空间中具有三个特征:
- 无序性,点云是一个集合,因此对顺序不敏感。目前文献中使用的方法包括将数据重排列、使用对称函数保证派别的不变性、用数据的所有排列进行数据增强;
- 点与点之间包含有意义的空间关系,为了有效使用这种空间关系,目前文献主张将局部特征和全局特征进行串联、特征直接聚合;
- 不变性,点云数据所代表的目标对某些空间转换具有不变性,比如旋转和平移。目前文献主张使用的方法包括引入各种具有不变性特征的算子、通过训练一个小型的网络来得到旋转矩阵,在特征提取之前对点云数据进行对齐。
深度学习的应用
目前三维点云在深度学习领域中的应用大体框架如图,主要分为:三维形状分类、三维目标检测及跟踪、三维点云分割。
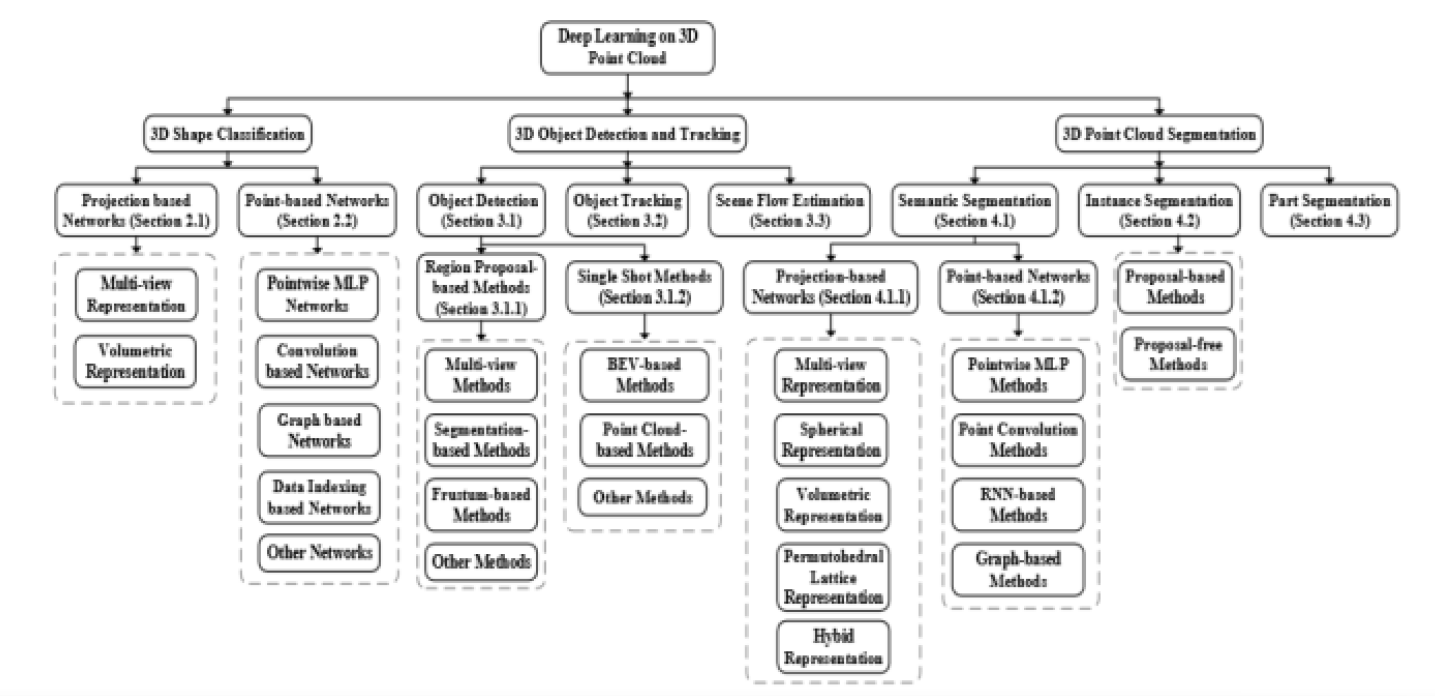
我们将点云在深度学习中的表示及处理方法大体分为如 下:
- 基于投影方法:基于投影的方法通常将非结构化的点云投影至中间的规则表示(即不同的表示模态),接着利用2D或者3D卷积来进行特征学习,实现最终的模型目标。目前学术界提出的表示模态包括:多视角表示、鸟瞰图表示、球状表示、体素表示、超多面体晶格表示以及混合表示。
- 基于点的方法:基于点的方法直接在原始数据上进行处理,并不需要体素化或是投影。基于点的方法不引入其它的信息损失且变得越来越流行。根据网络结构的不同,总体而言,这些方法可被简单的分为以下几类:基于各个点的MLP方法,基于点卷积的方法,基于RNN的方法和基于图的方法。
问题
基于三维数据的深度学习仍然存在着不少亟待解决的问题,我们整理了一些典型的问题:
- 基于点的网络是最常见的方法,然而,点的表示通常没有明确的邻域信息,大多数基于点的方法不得不试图使用好非自愿的邻域查找方法(KNN, ball query),而由于领域查找方法需要很高的计算资源和内存,自然也限制了这类方法的有效性;
- 在点云分割中,从不平衡的数据中学习仍然是具有挑战性的问题,尽管许多方法达到了不错的结果,但性能在较小类别的数据上仍然较差
- 由于三维数据处理占用了大量的算力,大多数的方法在较少点的点云上进行,但实际上从深度sensor上得到的点云是非常稠密的,因此需要寻求处理大规模点云的有效方法;
- 最近一些工作开始在动态点云中学习空间-时间的信息,空间-时间信息可以帮助提高3D目标检测,分割和补全是值得期待的。
FEATURED TAGS
Computer Vision
Colorization
Deep Learning
Papers
Technical Writing
Computer Graphics
Tutorials
Mathematics
Graph Neural Network
Biomedical
Natural Language Processing
Graph Theory
Neural Network
Reinforcement Learning
Markov Decision Process
Paper Reading
Games
GVGAI
VGDL
MCTS
Clustering
Unsupervised Machine Learning
Social Science