About Reinforcement Learning
Characteristics of Reinforcement Learning
- There is no supervisor, only a reward signal
- Feedback is delayed, not instantaneous
- Time really matters (sequential)
- Agent’s actions affect the subsequent data it receives
The Reinforcement Learning Problem
Rewards
- A reward \(R_t\) is a scalar feedback signal
- Indicates how well agent is doing at step \(t\)
- The agent’s job is to maximize cumulative reward
- Reinforcement learning is based on the reward hypothesis
Reward Hypothesis Definition: The goals can be described by the maximization of expected cumulative reward.
If a problem cannot satisfy with the reward hypothesis, it cannot solved by reinforcement learning.
Sequential Decision Making
- Goal: Select actions to maximize total future reward
- Actions may have long term consequences
- Reward may be delayed
- It may be better to sacrifice immediate reward to gain more long-term reward
Agent and Environment
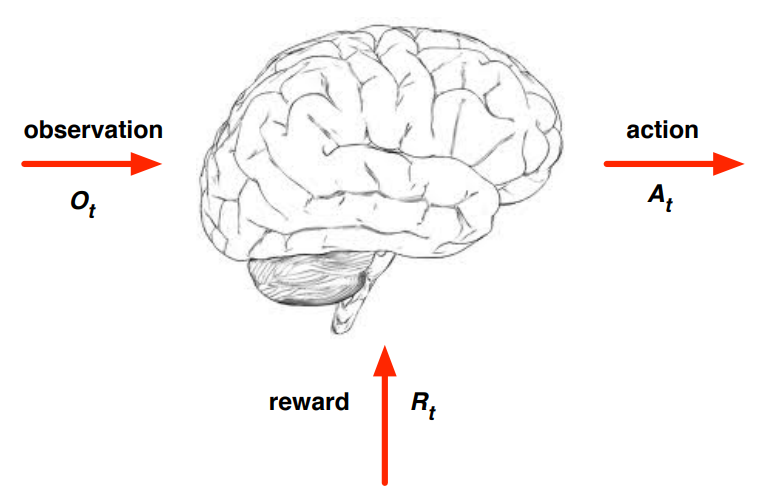
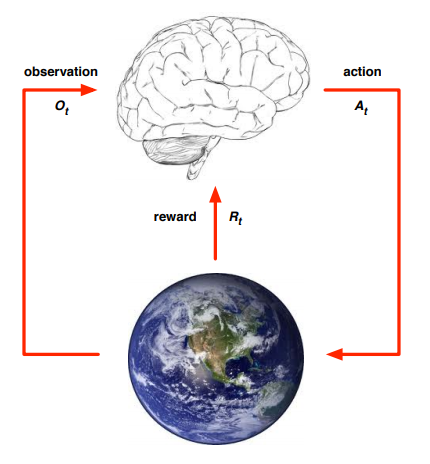
- At each step \(t\) the agent:
- Executes action \(a_t\)
- Receives observation \(o_t\)
- Receives scalar reward \(r_t\)
- The environment:
- Receives action \(a_t\)
- Emits observation \(o_{t+1}\)
- Emits scalar reward \(r_{t+1}\)
- \(t\) increments at env. step
History and State
The history is the sequence of observations, actions, and rewards:
\[H_t = a_1, o_1, r_1, \dots, a_t, o_t, r_t\]What happens next depends on the history:
- The agent selects actions
- The environment selects observations/rewards
State is the information used to determine what happens next. Formally, state is a function of the history:
\[s_t = f(H_t)\]Environment State
The environment state \(s_t^e\) is the environment’s private representation. The environment state is not usually visible to the agent. Even if it is visible, it may contain irrelevant information.
Agent State
The agent state \(s_t^a\) is the agent’s internal representation. It can be any function of history.
Information State (Markov State)
An information state (Markov state) contains all useful information from the history.
A state \(s_t\) is Markov if and only if
\[\mathbb{P}[s_{t+1}|s_t] = \mathbb{P}[s_{t+1}|s_1, \dots, s_t]\]The future is independent of the past given the present. Once the state is known, the history may be thrown away. The state is a sufficient statistic of the future.
Fully Observable Environments
Full observability: agent directly observes environment state
\[o_t = s_t^a = s_t^e\]Formally, this is a Markov decision process.
Partially Observable Environments
Partial observability: agent indirectly observes environment. Now \(s_t^a \neq \s_t^e\). Formally this is a partially observable markov decision process (POMDP).
Agent must construct its own state representation:
- Complete history: \(s_t^a = H_t\)
- Beliefs of environment state: \(s_t^a = (\mathbb{P}[s_t^e=s^1], \dots, \mathbb{P}[s_t^e=s^n])\)
- Recurrent Neural Network: \(s_t^a=\sigma(s_{t-1}^a W_s + o_tW_o)\)
Inside an RL Agent
Major Components of an RL Agent
- Policy: agent’s behavior function
- Its a map from state to action
- Deterministic policy: \(a=\pi (s)\)
- Stochastic policy: \(\pi(a \mid s) = \mathbb{P}[a_t=a \mid s_t =s])
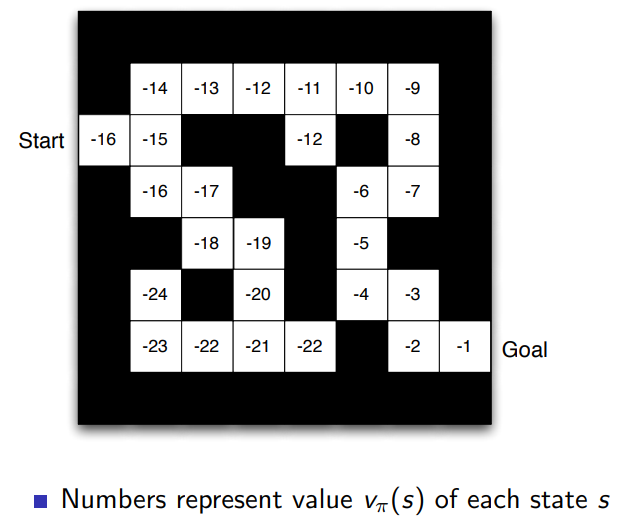
- Value function: how good is each state and/or action
- It is used to evaluate the goodness/badness of states
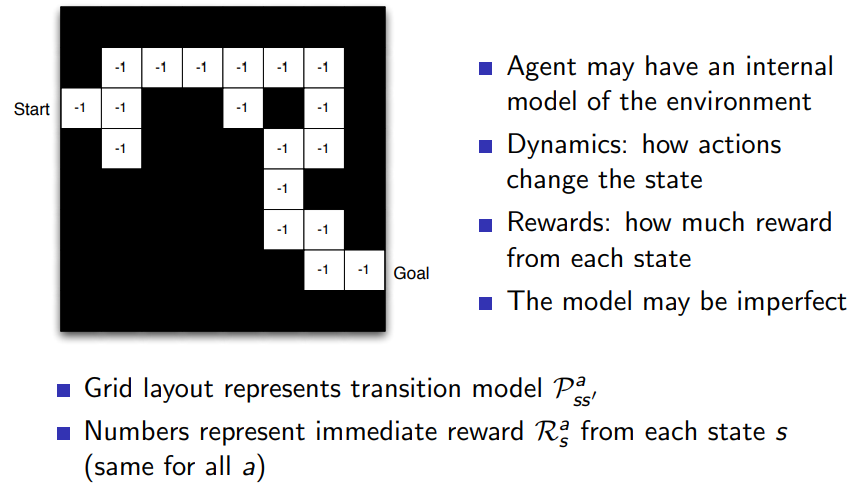
- Model: agent’s representation of the environment
- A model predicts what the environment will do next
- Transition model \(\mathcal{P}\) predicts the next state
- Reward model \(\mathcal{R}\) predicts the next reward
Value function:
\[v_\pi(s) = \mathbb{E}_\pi [R_{t+1} + \gamma R_{t+2} + \gamma^2R_{t+3} + \dots \mid s_t=s]\]Transition model:
\[\mathcal{P}_{ss'}^a=\mathbb{P}[s_{t+1}=s' \mid s_t=s, a_t=a]\]Reward model:
\[\mathcal{R}_s^a = \mathbb{E}[r_{t+1} \mid s_t=s, a_t=a]\]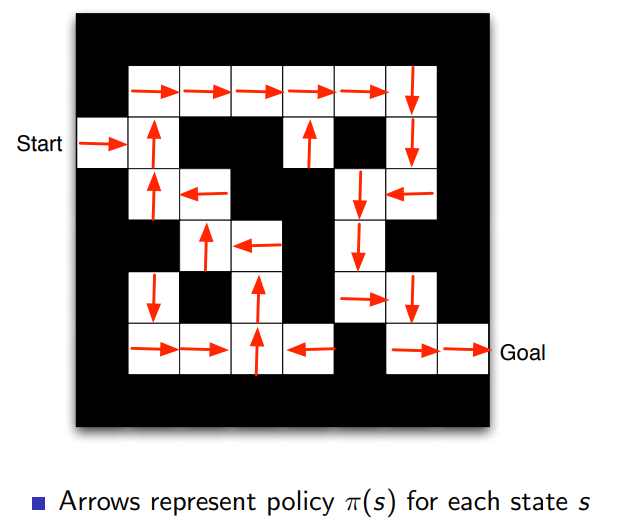
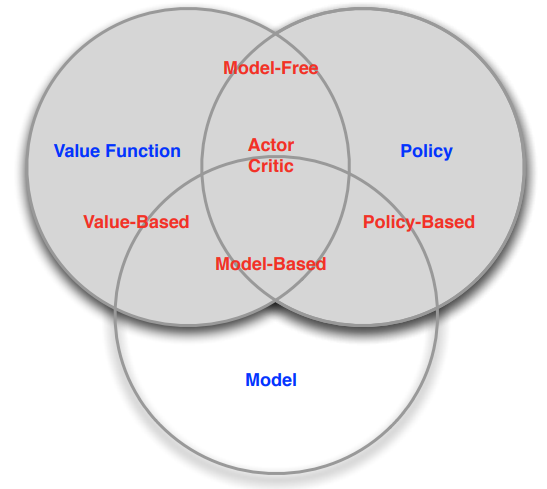
Categorizing RL Agents
- Value Based
- No Policy (implicit)
- Value Function
- Policy Based
- Policy
- No Value Function
- Actor Critic
- Policy
- Value Function
- Model Free
- Policy and/or Value Function
- No model
- Model Based
- Policy and/or Value Function
- Model
Problems Within RL
Two fundamental problems in sequential decision making.
RL and Planning
- Reinforcement Learning
- The environment is initially unknown
- The agent interacts with the environment
- The agent improves its policy
- Planning
- A model of the environment is known
- The agent performs computations with its model
- The agent improves its policy
- a.k.a deliberation, reasoning, introspection, pondering, thought, search
Exploration and Exploitation
Reinforcement learning is like trial-and-error learning. The agent should discover a good policy. From its experiences of the environment, without losing too much reward along the way.
- Exploration finds more information about the environment
- Exploitation exploits known information to maximize reward
It is usually important to explore as well as exploit
Prediction and Control
- Prediction: evaluate the future
- Given a policy
- Control: optimise the future
- Find the best policy