简介
虽然卷积神经网络(CNN)已经成为计算机视觉事实上的标准,但最近基于自注意力层的替代品 Vision Transformers(ViT)却获得了最先进的性能。ViT延续了从模型中消除手工特征和归纳偏差的长期趋势,并进一步依赖于从原始数据中学习。
本文提出了MLP-Mixer结构(简称为Mixer),它有竞争力并且在概念和技术上都很简单的替代品,它不适用卷积或自注意力。相反,Mixer的结构完全基于多层感知器,这些感知器可以重复应用于空间位置或特征通道。Mixer仅依赖于基本矩阵乘法,对数据布局的更改(重塑和换位)以及非线性标量。
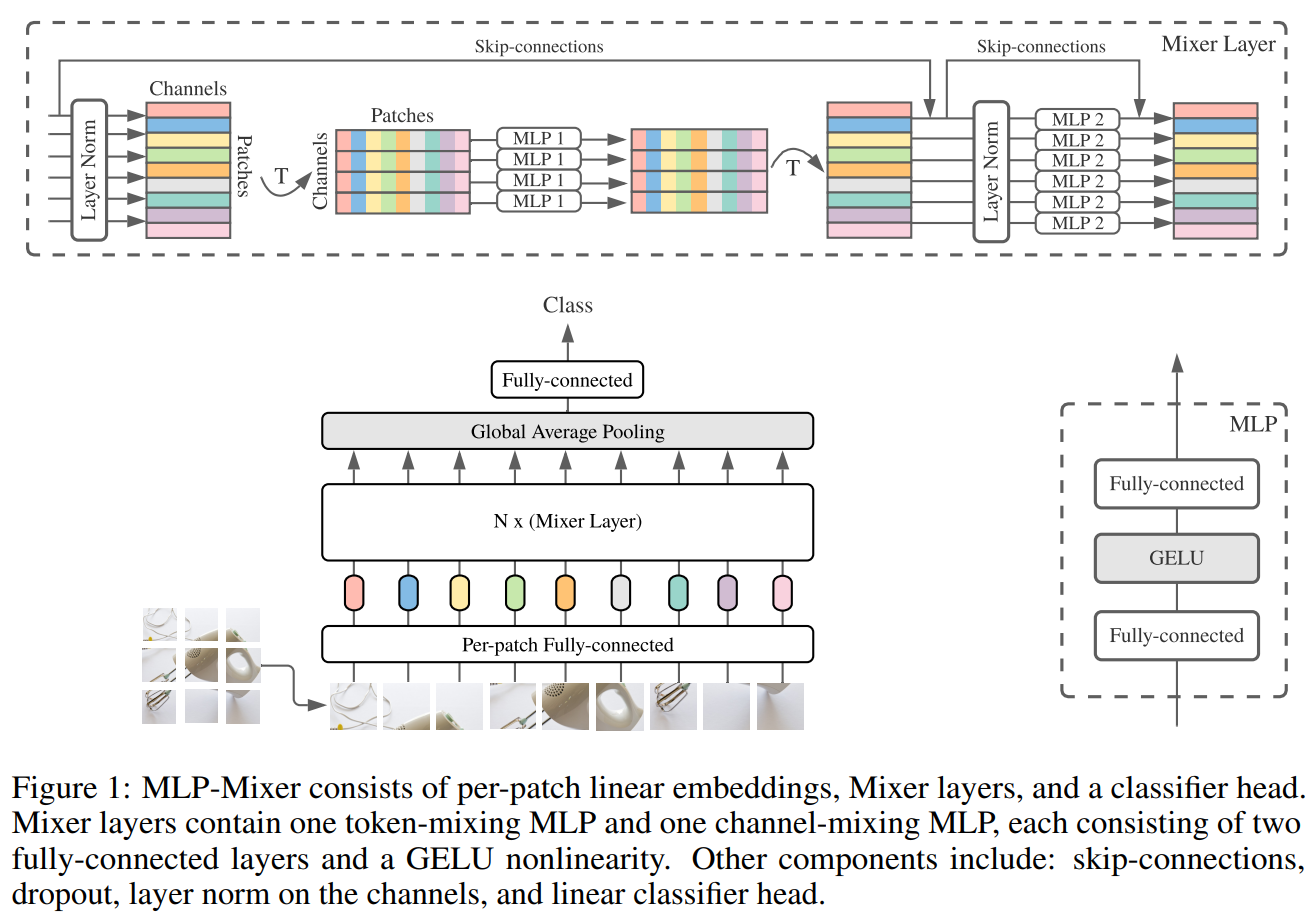
Figure 1描绘了Mixer的宏观结构。它以形状为 patches x channels表的一系列线性投影图像补丁(也称为标记)作为输入,并保持该维度。Mixer利用两种类型的MLP层,通道混合MLPs和符号混合MLPs。通道混合MLPs允许在不同通道之间进行通信,它们独立地对每个符号进行操作,并将表的各个行作为输入。符号混合MLPs允许不同空间位置(符号)之间通信;它们在每个通道上独立运行,并以表格的每个列作为输入。这两种类型的层是交错的,以实现两个输入维度的交互。
极端的说,这种结构可以看作是一个非常特殊的CNN,它使用 1x1卷积进行通道混合,并使用完整感受野的单通道深度卷积和符号混合的参数共享。此外,卷积比MLP中的普通矩阵乘法更为复杂,因为卷积需要对矩阵乘法和特殊实现实现进行额外的成本。
Mixer也具有令人瞩目的成绩。当在大数据集上与训练后(约一亿张图片),它基本上可以达到 SOTA水平。在ILSVRC2012上可以达到 87.94%第一的验证准确率。在更少量的数据集上训练时(大约一百万到一千万张),加入当代正则化技巧后,Mixer也可以去的较好的成绩,与ViT媲美,稍弱于特殊的CNN架构。
Mixer 架构
现代深度视觉架构由(1)在给定的空间位置(2)在不同的空间位置之间,或者这两者的组合混合特征的层组成。在 CNN 中,第二种层由 \(N \times N\)的卷积和池化层组成。在深度网络中,神经元具有巨大的感受野。与此同时,\(1\times 1\)的卷积层也可以执行第一种操作,更大的卷积核也可以同时执行以上两种。在Vision Transformers或其他基于注意力的架构中,自注意力层允许执行其两者,且MLP Block执行其一。Mixer架构背后的思想是将按位(通道混合)操作(1)和跨位操作(符号混合)操作(2)清楚地分开。两种操作都由MLP来实现。
再来看 Figure 1。Mixer将不互相重叠的图片区块序列 \(S\)作为输入,每个区块都能映射到所需的隐藏维度 \(C\)中,这将产生一个二维实值输入表,即 \(X \in \mathbb{R}^{S \times C}\)。元时输入图像的分辨率为 \((H, W)\),每个图片区块的大小为 \((P, P)\),那么区块的数量(序列的长度)\(S = HW / P^2\)。所有的区块都通过一个相同的映射矩阵线性映射。Mixer由相同大小的多层组成,每一层都包括两个 MLP Blocks。第一个是符号混合MLP Block:它作用于 \(X\)的列(即它应用于专职的输入表\(X^\top\)),映射\(\mathbb{R}^S\mapsto\mathbb{R}^S \),且与所有的列共享。第二个是通道混合MLP Block:它作用于\(X\)的行,映射\(\mathbb{R}^C\mapsto\mathbb{R}^C\),与所有的行共享。每个MLP Block包含两个全连接层和一个非线性激活函数独立地应用于其输入数据张量的每一行。Mixer层可以被写成(忽略层序号):
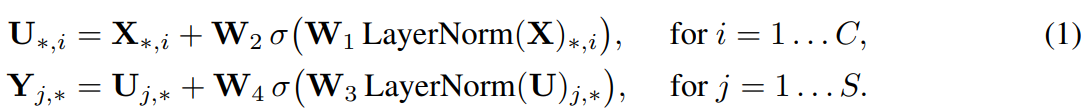
其中,\(\sigma\)是一个逐项非线性激活函数(GELU),\(D_s\)和 \(D_C\)分别是符号混合MLP和通道混合MLP中的可调隐藏宽度。注意这里 \(D_s\)的选择与输入区块的数量无关。因此,与ViT的平方复杂度不同,网络的计算复杂度在输入区块的数量上是线性的。由于 \(D_C\)与区块的代销无关,因此对于典型的CNN,总体复杂度在图像像素上是线性增加的。
正如前文提及的,相同的通道混合MLP(或符号混合MLP)应用于\(X\)的每一行(或列)。将通道混合MLP的参数(在每一层内)捆绑在一起是很自然的选择-它提供位置不变性,这是卷积的显着特征。 但是,跨通道绑定参数的情况要少得多。例如,可分离的卷积将卷积应用于每个通道,而与其他通道无关。但是,在可分离的卷积中,将不同的卷积内核应用于每个通道,这与Mixer中的符号混合MLP不同,后者对于所有通道共享同一内核(具有完整的感受野)。当增加隐藏维度 \(C\)或序列长度 \(S\)时,参数绑定可以防止体系结构增长过快,并节省大量内存。这种选择并不影响性能,请参阅附录 A.1。
Mixer中的每个层(初始区块投影层除外)都采用相同大小的输入。 这种“各向同性”的设计与其他使用固定宽度的Transformer或其他领域的Deep RNN最相似。这与大多数具有金字塔结构的CNN不同:更深的层具有较低的分辨率输入,但具有更多的通道。 注意,尽管这些是典型的设计,但也存在其他组合,例如各向同性ResNets和金字塔形ViT。
除了MLP层,Mixer还使用其他标准体系结构组件:跳跃连接和层规范化。此外,与ViT不同,Mixer不使用Position Embeddings,因为符号混合MLP对输入符号的顺序很敏感,因此可以学会表示位置。 最后,Mixer使用带有全局平均池化层的标准分类头,然后是线性分类器。总体而言,该体系结构可以用JAX / Flax紧凑地编写,其代码在附录E中给出。
实验
我们对三个量感兴趣:(1)下游任务的准确性。 (2)预训练的总计算成本,这对于在上游数据集上从头开始训练模型时非常重要。 (3)推理时的吞吐量,这对于从业者很重要。
下游任务
在 ILSVRC2012 ImageNet,CIFAR-10/100,Oxford-IIIT Pets,Oxford Flowers-102,Visual Task Adaptation Benchmark任务中测试。
预训练数据
两个公开数据集:ILSVRC2021 ImageNet,ImageNet-21k。另外还在 JFT-300M上进行训练,三亿张图片18万类。
预训练细节
Adam with \(\beta_1 = 0.9, \beta_2 = 0.999\),批大小为4096,使用权重衰减,全局标准1的梯度裁剪。我们使用前1万步的线性学习速率预热和线性衰减。与训练模型的输入大小皆为\(224\times 224\)分辨率。